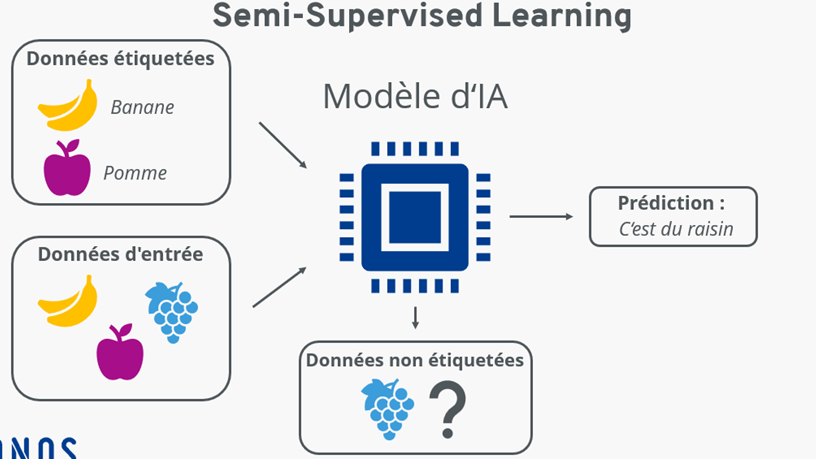
Dans le monde fascinant de l’intelligence artificielle, les exemples dans l’apprentissage des étiquetés sont cruciaux pour guider les algorithmes. Avez-vous déjà pensé à la manière dont ces systèmes apprennent à reconnaître des images ou à interpréter des données ? En utilisant des données étiquetées, nous fournissons aux algorithmes un cadre qui leur permet d’améliorer leurs performances et de devenir plus précis.
Les Fondements de l’Apprentissage Supervisé
L’apprentissage supervisé repose sur des principes essentiels qui guident les algorithmes dans leur processus d’apprentissage. Ces principes incluent :
Nous comprenons également qu’une fois ces étapes mises en œuvre, il est crucial d’évaluer la performance du modèle. Les indicateurs comme la précision, le rappel et la courbe ROC fournissent un aperçu clair.
De plus, nous devons prêter attention à l’importance des retours d’expérience. En intégrant des ajustements basés sur ces retours, nous améliorons continuellement notre modèle.
En somme, chaque élément joue un rôle clé dans l’efficacité globale de l’apprentissage supervisé. Le choix judicieux des exemples étiquetés ainsi que leur traitement correct garantissent une meilleure formation pour nos algorithmes.
Importance des Exemples Étiquetés
Les exemples étiquetés jouent un rôle crucial dans l’apprentissage supervisé. Ils fournissent aux algorithmes les données nécessaires pour effectuer des prédictions précises. Sans ces exemples, le modèle ne pourrait pas apprendre efficacement.
Rôle dans le Processus d’Apprentissage
Le processus d’apprentissage repose sur plusieurs étapes fondamentales où les exemples étiquetés sont essentiels :
Nous constatons donc que chaque étape dépend de la qualité et de la quantité des exemples fournis.
Impact sur la Précision des Modèles
L’impact des exemples étiquetés sur la précision est significatif :
En résumé, nous réalisons que l’utilisation adéquate d’exemples étiquetés influence directement l’efficacité et la fiabilité des modèles développés.
Types d’Exemples Étiquetés
Nous allons explorer les différentes catégories d’exemples étiquetés, qui jouent un rôle crucial dans l’apprentissage supervisé. Ces exemples permettent aux algorithmes de développer des modèles précis et adaptés à diverses tâches.
Exemples de Données d’Entraînement
Les exemples de données d’entraînement constituent la base pour former nos modèles. Ils fournissent des informations essentielles afin que les algorithmes puissent apprendre à prédire ou classer correctement. Voici quelques types courants :
Ces données doivent être diversifiées et représentatives pour garantir une bonne généralisation du modèle.
Exemples de Données de Test
Les exemples de données de test servent à valider la performance des modèles après leur entraînement. Ils permettent d’évaluer si l’algorithme peut bien fonctionner sur des données non vues. Les points suivants illustrent leur importance :
L’utilisation judicieuse des exemples de test permet ainsi d’affiner continuellement nos algorithmes tout en garantissant une meilleure performance globale.
Méthodes pour Fournir des Exemples à l’Algorithme
La fourniture d’exemples étiquetés à un algorithme nécessite des méthodes adaptées. Ces méthodes garantissent une qualité de données qui influence directement la performance du modèle. Explorons les techniques et stratégies clés.
Techniques de Collecte des Données
Pour collecter efficacement des données étiquetées, nous pouvons utiliser plusieurs techniques :
Chacune de ces techniques permet d’obtenir des exemples variés et pertinents, augmentant ainsi la diversité nécessaire pour entraîner nos algorithmes.
Stratégies de Sélection des Étiquettes
La sélection adéquate des étiquettes est cruciale pour garantir la précision du modèle. Voici quelques stratégies efficaces :
En appliquant ces stratégies, nous assurons que les exemples fournis sont non seulement précis mais aussi représentatifs, renforçant ainsi l’efficacité globale du processus d’apprentissage supervisé.
Conclusions Clés
L’importance des exemples d’apprentissage étiquetés dans l’intelligence artificielle ne peut être sous-estimée. Ils constituent la base même de l’apprentissage supervisé et permettent aux algorithmes de progresser avec précision. En nous concentrant sur la qualité des données et les méthodes de collecte appropriées, nous nous assurons que nos modèles sont non seulement performants mais également robustes face à diverses situations.
À travers une approche systématique qui inclut la validation croisée et l’évaluation continue, nous pouvons affiner notre compréhension et améliorer constamment nos algorithmes. Cela renforce notre capacité à obtenir des résultats fiables tout en minimisant le risque de surajustement. L’efficacité du processus d’apprentissage dépend largement de ces pratiques essentielles que nous adoptons dans notre travail quotidien.